CAP Theorem 的 CAP 分別是指:
- C (Strong Consistency): 在任何時候,從叢集中的任兩個節點得到的狀態都是一樣的。
- A (Availability): 若一個節點沒有壞掉,那它就必須要能正常服務。
- P (Partition Tolerance): 若一個叢集因網路問題或節點故障問題,被切割成兩個(或以上)不完整的sub cluster時,系統整體還能正常運作。
分散式系統中,這三個特性至多只有兩個能同時存在。
假設有兩台節點在不同機器上,如果存入資料的方式是Two-phase commit,亦即所有節點同意後才能存入資料,那麼只要partition發生、或任何一個節點故障,就不能運作,因此就只有C和A。但這樣的系統實在是太脆弱了(記得day 4 把查詢灑到所有機器執行的風險嗎?),所以一般的分散式系統都會要求要有P。
假設有兩台節點在不同機器上,且必須要能容忍Partition,那麼在partition發生時能怎麼做呢?
- Keep Availability:兩個節點雖然彼此之間不能溝通,但是既然都活著,就讓他們都正常服務好了。這樣其中一邊的變化不能傳遞至另外一邊,因此可能兩邊資料會不一致 。更糟的狀況是發生裂腦,就兩邊都以為自己是master可以寫入資料,就會產生前兩天提到的時序問題。(No consistency -- A和P)
- Keep Consistency: 為了避免之前提到的不一致問題,因此必須停掉其中任一個節點 (No availability -- C和P)
網路上CAP的圖很多,比方說這一張:
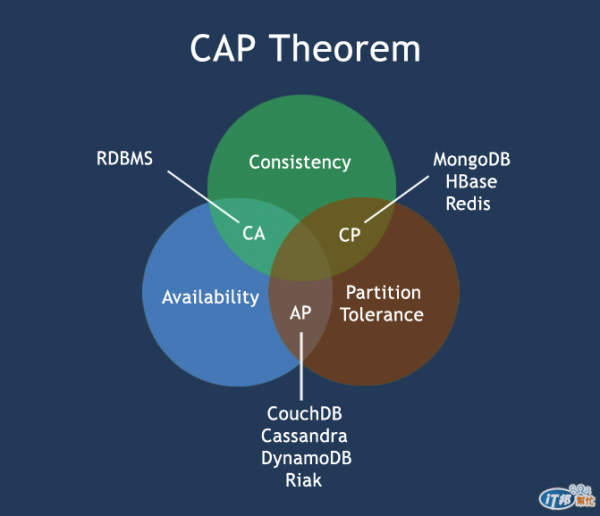
Source: http://www.w3resource.com/mongodb/nosql.php
沒有意外的話,明天應該會講一下Zookeeper,Zookeeper是偏向CP的設計,至於為什麼呢?等明天再說好了。


 iThome鐵人賽
iThome鐵人賽